|
| | IntrinsicPlasticity (int nodes, double mu, double stdDev=1.0) |
| |
| virtual unsigned int | examples () |
| | Request number of training examples. More...
|
| |
| virtual unsigned int | dimension () |
| | Request the number of optimizable parameters. More...
|
| |
| virtual bool | providesInitialization () |
| | Check if the object knows how to initialize its parameters. More...
|
| |
| virtual void | initialize () |
| | Initialize the optimizable parameters. More...
|
| |
| virtual double | error () |
| | Compute error on training set. More...
|
| |
| virtual double | error (unsigned int n) |
| |
| virtual const Eigen::VectorXd & | currentParameters () |
| | Request the current parameters. More...
|
| |
| virtual void | setParameters (const Eigen::VectorXd ¶meters) |
| | Set new parameters. More...
|
| |
| virtual bool | providesGradient () |
| | Check if the object provides a gradient of the error function with respect to its parameters. More...
|
| |
| virtual Eigen::VectorXd | gradient () |
| | Compute gradient of the error function with respect to the parameters. More...
|
| |
| virtual Eigen::VectorXd | gradient (unsigned int n) |
| |
| virtual Eigen::VectorXd | operator() (const Eigen::VectorXd &a) |
| | Make a prediction. More...
|
| |
| virtual Eigen::MatrixXd | operator() (const Eigen::MatrixXd &A) |
| | Make predictions. More...
|
| |
| virtual OutputInfo | initialize (std::vector< double * > ¶meterPointers, std::vector< double * > ¶meterDerivativePointers) |
| | Fill in the parameter pointers and parameter derivative pointers. More...
|
| |
| virtual void | initializeParameters () |
| | Initialize the parameters. More...
|
| |
| virtual void | updatedParameters () |
| | Generate internal parameters from externally visible parameters. More...
|
| |
| virtual void | forwardPropagate (Eigen::MatrixXd *x, Eigen::MatrixXd *&y, bool dropout, double *error=0) |
| | Forward propagation in this layer. More...
|
| |
| virtual void | backpropagate (Eigen::MatrixXd *ein, Eigen::MatrixXd *&eout, bool backpropToPrevious) |
| | Backpropagation in this layer. More...
|
| |
| virtual Eigen::MatrixXd & | getOutput () |
| | Output after last forward propagation. More...
|
| |
| virtual Eigen::VectorXd | getParameters () |
| | Get the current values of parameters (weights, biases, ...). More...
|
| |
| | Learner () |
| |
| virtual | ~Learner () |
| |
| virtual Learner & | trainingSet (Eigen::MatrixXd &input, Eigen::MatrixXd &output) |
| | Set training set. More...
|
| |
| virtual Learner & | trainingSet (DataSet &trainingSet) |
| | Set training set. More...
|
| |
| virtual Learner & | removeTrainingSet () |
| | Remove the training set from the learner. More...
|
| |
| virtual Learner & | validationSet (Eigen::MatrixXd &input, Eigen::MatrixXd &output) |
| | Set validation set. More...
|
| |
| virtual Learner & | validationSet (DataSet &validationSet) |
| | Set validation set. More...
|
| |
| virtual Learner & | removeValidationSet () |
| | Remove the validation set from the learner. More...
|
| |
| virtual | ~Optimizable () |
| |
| virtual void | finishedIteration () |
| | This callback is called after each optimization algorithm iteration. More...
|
| |
| virtual double | error (unsigned n) |
| | Compute error of a given training example. More...
|
| |
| virtual Eigen::VectorXd | gradient (unsigned n) |
| | Compute gradient of a given training example. More...
|
| |
| virtual void | errorGradient (int n, double &value, Eigen::VectorXd &grad) |
| | Calculates the function value and gradient of a training example. More...
|
| |
| virtual void | errorGradient (double &value, Eigen::VectorXd &grad) |
| | Calculates the function value and gradient of all training examples. More...
|
| |
| virtual Eigen::VectorXd | error (std::vector< int >::const_iterator startN, std::vector< int >::const_iterator endN) |
| | Calculates the errors of given training examples. More...
|
| |
| virtual Eigen::VectorXd | gradient (std::vector< int >::const_iterator startN, std::vector< int >::const_iterator endN) |
| | Calculates the accumulated gradient of given training examples. More...
|
| |
| virtual void | errorGradient (std::vector< int >::const_iterator startN, std::vector< int >::const_iterator endN, double &value, Eigen::VectorXd &grad) |
| | Calculates the accumulated gradient and error of given training examples. More...
|
| |
| virtual | ~Layer () |
| |
Learns the parameters of a logistic sigmoid activation function.
Activation functions of the form 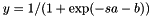 with slopes
with slopes 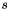 and biases
and biases 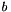 are adapted such that the output distribution is approximately exponential with mean
are adapted such that the output distribution is approximately exponential with mean 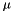 and with respect to a input distribution given by a training set. This procedure prevents saturation. Note that changing the incoming weights might require readjustment.
and with respect to a input distribution given by a training set. This procedure prevents saturation. Note that changing the incoming weights might require readjustment.
[1] Jochen Triesch: A Gradient Rule for the Plasticity of a Neuron’s Intrinsic Excitability, Proceedings of the International Conference on Artificial Neural Networks, pp. 1–7, 2005.
[2] Jochen Triesch: Synergies between intrinsic and synaptic plasticity mechanisms, Neural Computation 19, pp. 885-909, 2007.


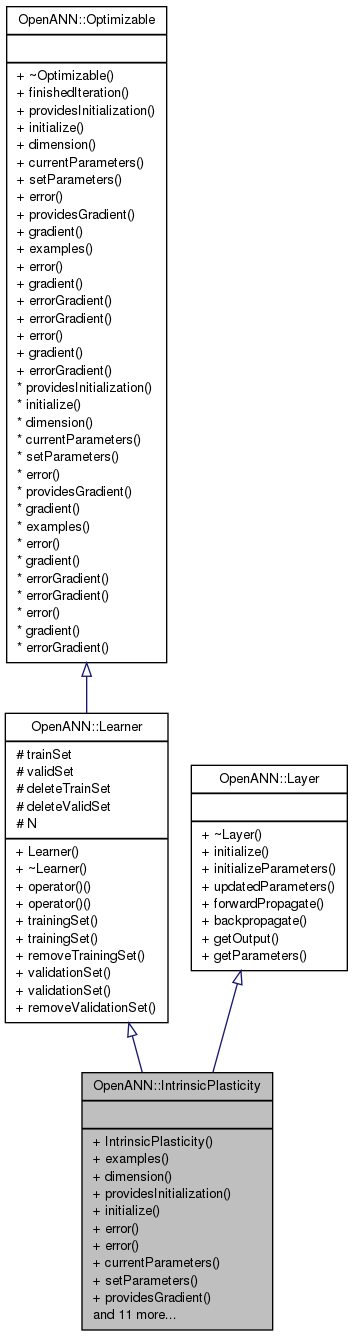
 Inheritance diagram for OpenANN::IntrinsicPlasticity:
Inheritance diagram for OpenANN::IntrinsicPlasticity: 1.8.4
1.8.4