|
OpenANN
1.1.0
An open source library for artificial neural networks.
|


All Classes Namespaces Files Functions Variables Typedefs Enumerations Enumerator Friends Macros Pages
|
OpenANN
1.1.0
An open source library for artificial neural networks.
|
Mini-batch stochastic gradient descent. More...
#include <MBSGD.h>
 Inheritance diagram for OpenANN::MBSGD:
Inheritance diagram for OpenANN::MBSGD:Public Member Functions | |
| MBSGD (double learningRate=0.01, double momentum=0.5, int batchSize=10, bool nesterov=false, double learningRateDecay=1.0, double minimalLearningRate=0.0, double momentumGain=0.0, double maximalMomentum=1.0, double minGain=1.0, double maxGain=1.0) | |
| Create mini-batch stochastic gradient descent optimizer. More... | |
| ~MBSGD () | |
| virtual void | setOptimizable (Optimizable &opt) |
| Pass the objective function. More... | |
| virtual void | setStopCriteria (const StoppingCriteria &stop) |
| Pass the stop criteria. More... | |
| virtual void | optimize () |
| Optimize until the optimization meets the stop criteria. More... | |
| virtual bool | step () |
| Execute one optimization step. More... | |
| virtual Eigen::VectorXd | result () |
| Determine the best result. More... | |
| virtual std::string | name () |
| Get the name of the optimization algorithm. More... | |
| Public Member Functions inherited from OpenANN::Optimizer | |
| virtual | ~Optimizer () |
Mini-batch stochastic gradient descent.
This implementation of gradient descent has some modifications:
A good introduction to optimization with MBSGD can be found in Geoff Hinton's Coursera course "Neural Networks for Machine Learning". A detailed description of this implementation follows.
When the batch size equals 1, the algorithms degenerates to stochastic gradient descent. When it equals the training set size, the algorithm is like batch gradient descent.
Standard mini-batch stochastic gradient descent updates the weight vector w in step t through
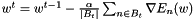
or
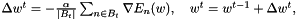
where 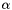 is the learning rate and
is the learning rate and 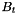 is the set of indices of the t-th mini-batch, which is drawn randomly. The random order of gradients prevents us from getting stuck in local minima. This is an advantage over batch gradient descent. However, we must not make the batch size too small. A bigger batch size makes the optimization more robust against noise of the training set. A reasonable batch size is between 10 and 100. The learning rate has to be within [0, 1). High learning rates can result in divergence, i.e. the error increases. Too low learning rates might make learning too slow, i.e. the number of epochs required to find an optimum might be infeasibe. A reasonable value for :math:
is the set of indices of the t-th mini-batch, which is drawn randomly. The random order of gradients prevents us from getting stuck in local minima. This is an advantage over batch gradient descent. However, we must not make the batch size too small. A bigger batch size makes the optimization more robust against noise of the training set. A reasonable batch size is between 10 and 100. The learning rate has to be within [0, 1). High learning rates can result in divergence, i.e. the error increases. Too low learning rates might make learning too slow, i.e. the number of epochs required to find an optimum might be infeasibe. A reasonable value for :math:\\alpha is usually within [1e-5, 0.1].
A momentum can increase the optimization stability. In this case, the update rule is
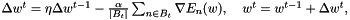
where 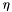 is called momentum and must lie in [0, 1). The momentum term incorporates past gradients with exponentially decaying influence. This reduces changes of the search direction. An intuitive explanation of this update rule is: we regard w as the position of a ball that is rolling down a hill. The gradient represents its acceleration and the acceleration modifies its momentum.
is called momentum and must lie in [0, 1). The momentum term incorporates past gradients with exponentially decaying influence. This reduces changes of the search direction. An intuitive explanation of this update rule is: we regard w as the position of a ball that is rolling down a hill. The gradient represents its acceleration and the acceleration modifies its momentum.
Another type of momentum that is available in this implementation is the Nesterov's accelerated gradient (NAG). For smooth convex functions, NAG achieves a convergence rate of 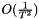 instead of
instead of 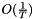 [1]. The update rule only differs in where we calculate the gradient.
[1]. The update rule only differs in where we calculate the gradient.
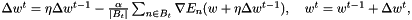
Another trick is using different learning rates for each weight. For each weight 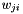 we can introduce a gain
we can introduce a gain 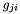 which will be multiplied with the learning rate so that we obtain an update rule for each weight
which will be multiplied with the learning rate so that we obtain an update rule for each weight
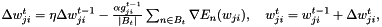
where 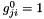 and will be increased by 0.05 if
and will be increased by 0.05 if 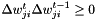 , i.e. the sign of the search direction did not change and will be multiplied by 0.95 otherwise. We set a minimum and a maximum value for each gain. Usually these are 0.1 and 10 or 0.001 and 100 respectively.
, i.e. the sign of the search direction did not change and will be multiplied by 0.95 otherwise. We set a minimum and a maximum value for each gain. Usually these are 0.1 and 10 or 0.001 and 100 respectively.
During optimization it often makes sense to start with a more global search, i.e. with a high learning rate and decrease the learning rate as we approach the minimum so that we obtain an update rule for the learning rate:
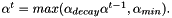
In addition, we can allow the optimizer to change the search direction more often at the beginning of the optimization and reduce this possibility at the end. To do this, we can start with a low momentum and increase it over time until we reach a maximum:
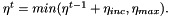
[1] Sutskever, Ilya; Martens, James; Dahl, George; Hinton, Geoffrey: On the importance of initialization and momentum in deep learning, International Conference on Machine Learning, 2013.
| OpenANN::MBSGD::MBSGD | ( | double | learningRate = 0.01, |
| double | momentum = 0.5, |
||
| int | batchSize = 10, |
||
| bool | nesterov = false, |
||
| double | learningRateDecay = 1.0, |
||
| double | minimalLearningRate = 0.0, |
||
| double | momentumGain = 0.0, |
||
| double | maximalMomentum = 1.0, |
||
| double | minGain = 1.0, |
||
| double | maxGain = 1.0 |
||
| ) |
Create mini-batch stochastic gradient descent optimizer.
| learningRate | learning rate (usually called alpha); range: (0, 1] |
| momentum | momentum coefficient (usually called eta); range: [0, 1) |
| batchSize | size of the mini-batches; range: [1, N], where N is the size of the training set |
| nesterov | use nesterov's accelerated momentum |
| learningRateDecay | will be multiplied with the learning rate after each weight update; range: (0, 1] |
| minimalLearningRate | minimum value for the learning rate; range: [0, 1] |
| momentumGain | will be added to the momentum after each weight update; range: [0, 1) |
| maximalMomentum | maximum value for the momentum; range [0, 1] |
| minGain | minimum factor for individual learning rates |
| maxGain | maximum factor for individual learning rates |
| OpenANN::MBSGD::~MBSGD | ( | ) |
|
virtual |
Get the name of the optimization algorithm.
Implements OpenANN::Optimizer.
|
virtual |
Optimize until the optimization meets the stop criteria.
Implements OpenANN::Optimizer.
|
virtual |
Determine the best result.
Implements OpenANN::Optimizer.
|
virtual |
Pass the objective function.
| optimizable | objective function, e. g. error function of an ANN |
Implements OpenANN::Optimizer.
|
virtual |
Pass the stop criteria.
| sc | the parameters used to stop the optimization |
Implements OpenANN::Optimizer.
|
virtual |
Execute one optimization step.
Implements OpenANN::Optimizer.
 1.8.4
1.8.4