|
OpenANN
1.1.0
An open source library for artificial neural networks.
|


All Classes Namespaces Files Functions Variables Typedefs Enumerations Enumerator Friends Macros Pages
|
OpenANN
1.1.0
An open source library for artificial neural networks.
|
This benchmark is based on the example Pole Balancing.
We compare the number of episodes that is needed to learn a successful policy. We use a Single Layer Perceptron (SLP) to represent the policy 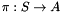 . In case of a partially observable environment, we estimate the velocities either with
. In case of a partially observable environment, we estimate the velocities either with 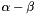 filters or by double exponential smoothing. We do 1000 runs per configuration. The output of the program could be
filters or by double exponential smoothing. We do 1000 runs per configuration. The output of the program could be
SPB, MDP, uncompressed .................................................................................................... 0/1000 failed episodes: 33.088+-20.8315 range: [1,142] median: 28 time: 118.6 ms SPB, MDP, compressed (1) .................................................................................................... 0/1000 failed episodes: 2.476+-2.4391 range: [1,40] median: 2 time: 104.3 ms DPB, MDP, uncompressed .................................................................................................... 0/1000 failed episodes: 261.146+-174.2955 range: [28,1410] median: 224 time: 210.9 ms DPB, MDP, compressed (5) .................................................................................................... 0/1000 failed episodes: 201.384+-229.8003 range: [10,1336] median: 139 time: 159.6 ms SPB, POMDP (ABF), uncompressed .................................................................................................... 0/1000 failed episodes: 31.381+-15.4108 range: [1,102] median: 30 time: 117.2 ms SPB, POMDP (ABF), compressed (3) .................................................................................................... 0/1000 failed episodes: 14.318+-9.5876 range: [1,57] median: 12 time: 114.2 ms DPB, POMDP (ABF), uncompressed .................................................................................................... 0/1000 failed episodes: 425.499+-220.8568 range: [3,1714] median: 388 time: 228.7 ms DPB, POMDP (ABF), compressed (5) .................................................................................................... 0/1000 failed episodes: 434.321+-318.3513 range: [25,1909] median: 352 time: 195.4 ms SPB, POMDP (DES), uncompressed .................................................................................................... 0/1000 failed episodes: 25.485+-15.8919 range: [1,97] median: 22 time: 209.3 ms SPB, POMDP (DES), compressed (3) .................................................................................................... 0/1000 failed episodes: 12.169+-7.9433 range: [1,56] median: 11 time: 149.2 ms DPB, POMDP (DES), uncompressed .................................................................................................... 0/1000 failed episodes: 225.166+-196.6204 range: [27,1532] median: 173 time: 584.4 ms DPB, POMDP (DES), compressed (5) .................................................................................................... 0/1000 failed episodes: 203.143+-241.2319 range: [7,1331] median: 133 time: 322.9 ms
Here SPB means Single Pole Balancing, DPB Double Pole Balancing, MDP (Fully Observable) Markov Decision Process, POMDP Partially Observable Markov Decision Process, ABF Filters, DES Double Exponential Smoothing (with 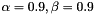 ). The number of compressed SLPs' parameters are given in brackets.
). The number of compressed SLPs' parameters are given in brackets.
 1.8.4
1.8.4